The Last 100+ Days
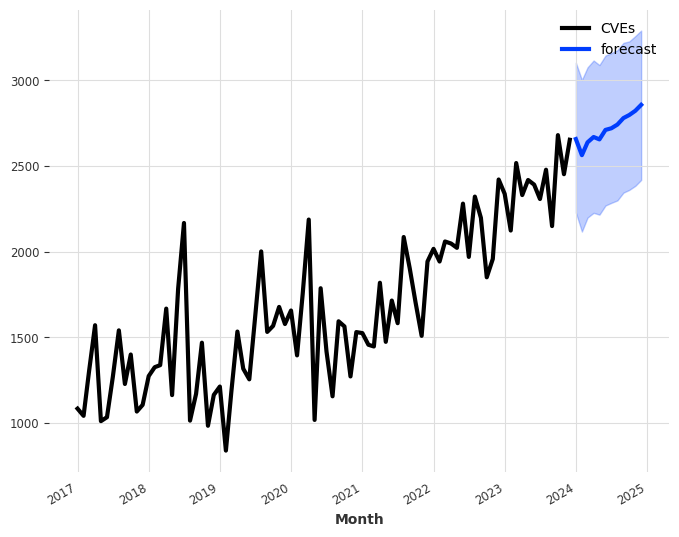
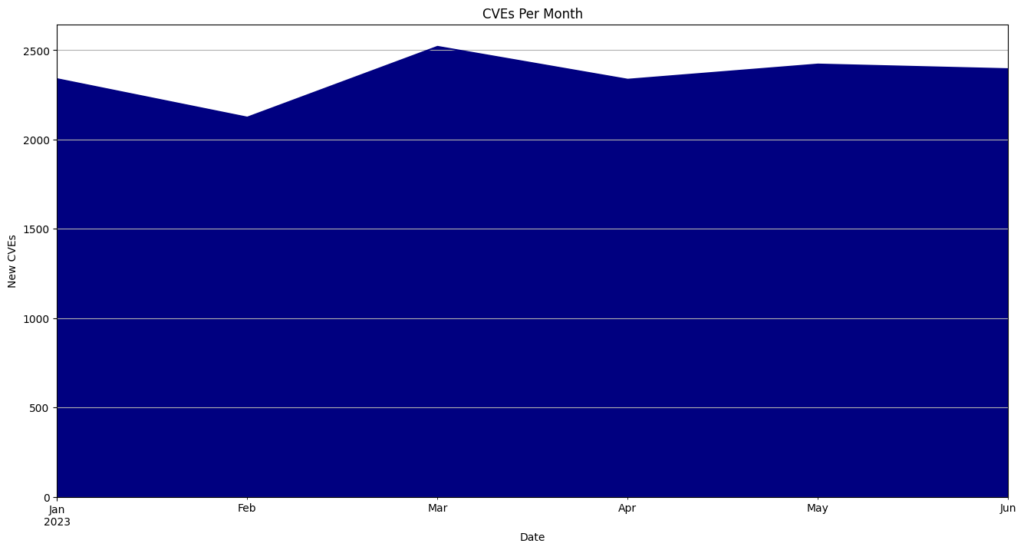
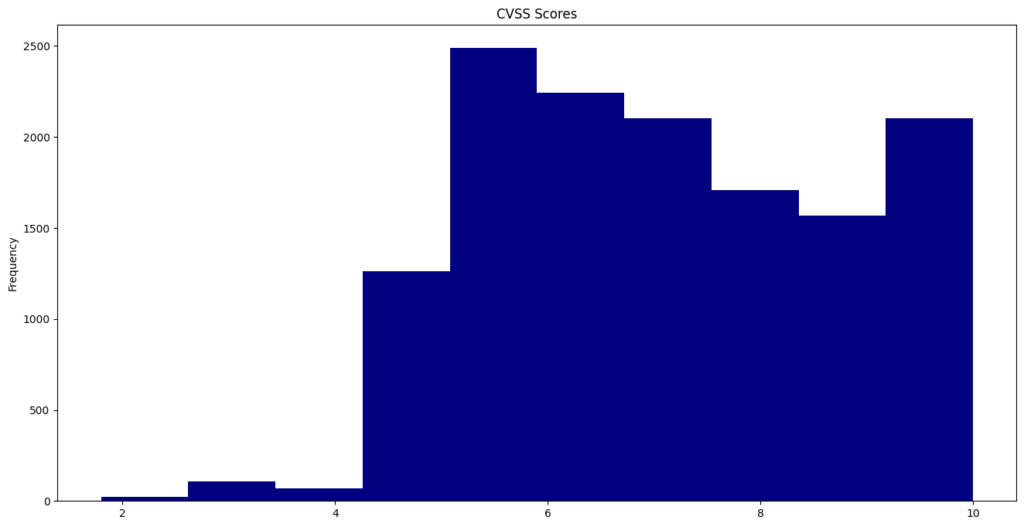
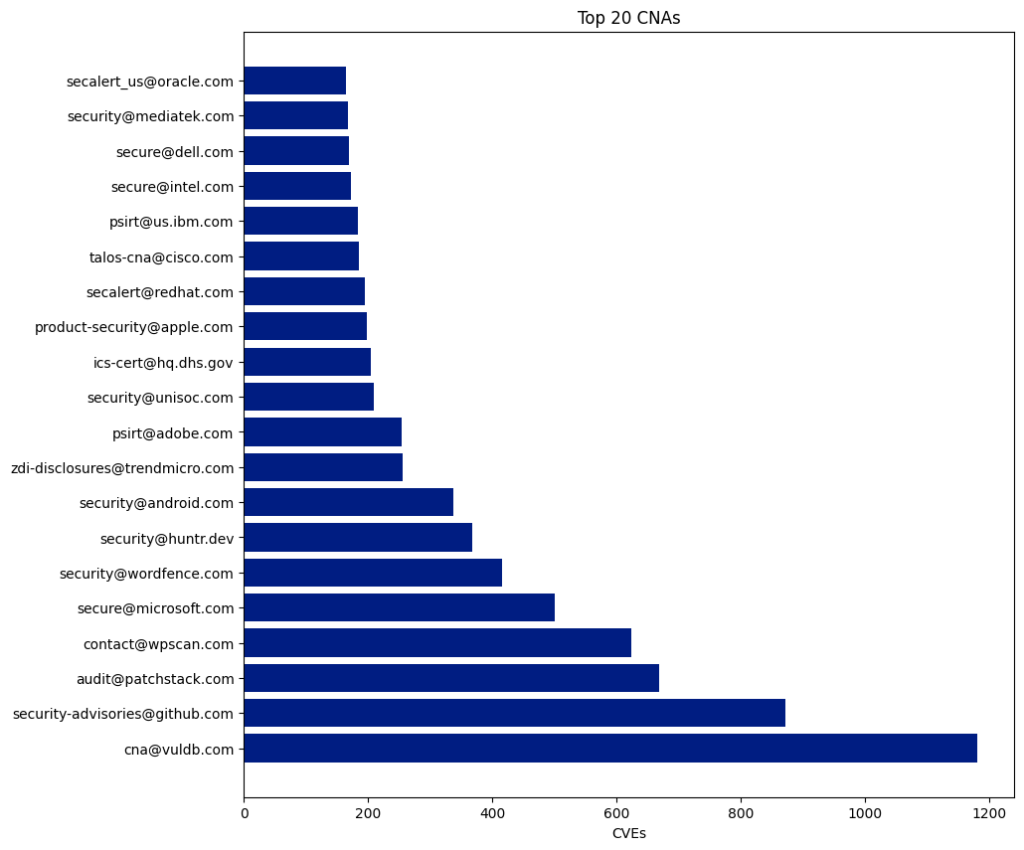
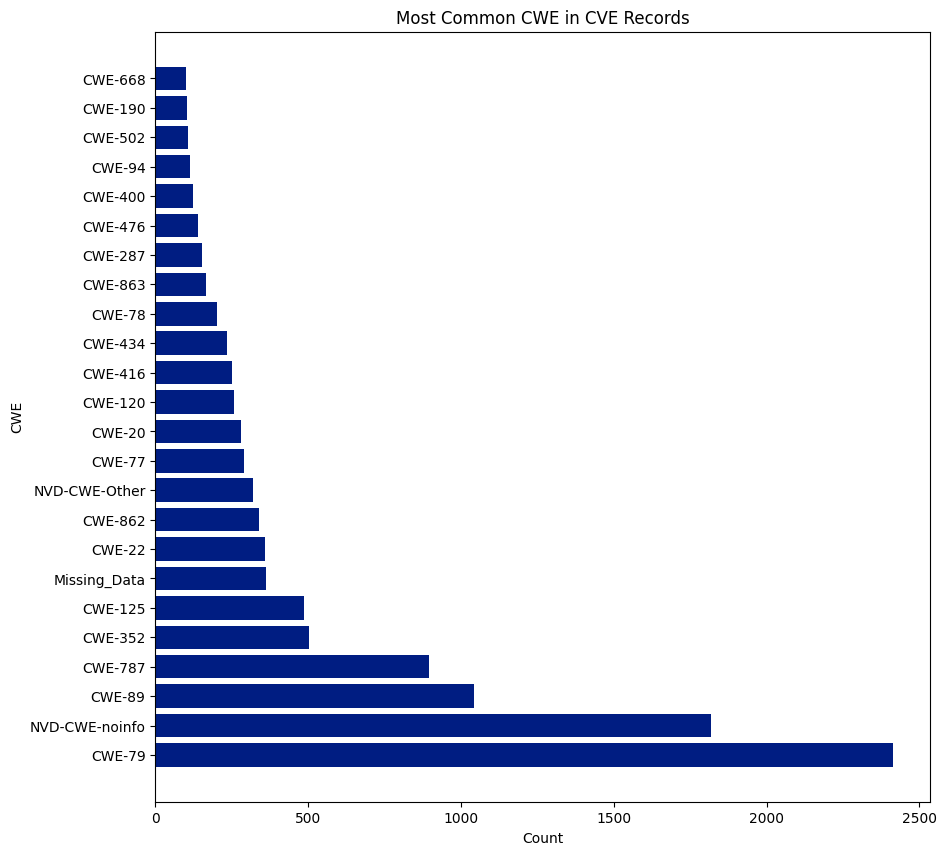
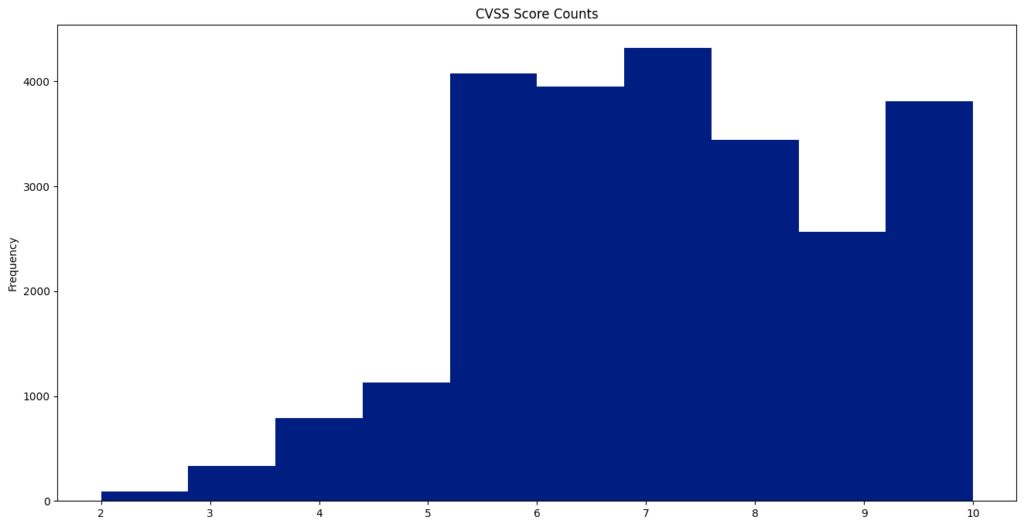
The NVD posted the notice below on its webpage in mid-February. Since then, nearly 13,000 CVEs have not been enriched with CWE, CVSS, and CPE data.

The vulnerability management community was told that it would be addressed at Vulncon this year. At the conference, we were told the enrichment would restart “in the next couple of days” and that a “consortium was being founded” to help guide the NVD. I left hopeful about the NVD’s future and tried hard to present a positive outlook. I spent time defending NVD as the source of the truth at work and in the community, waiting for the enrichment to continue, and closely tracking the backlog as it grew.
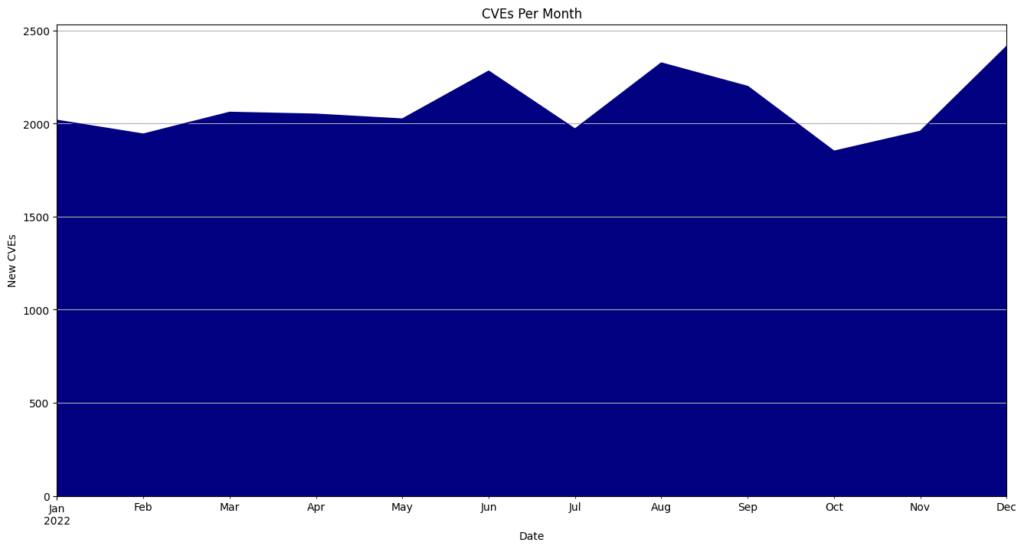
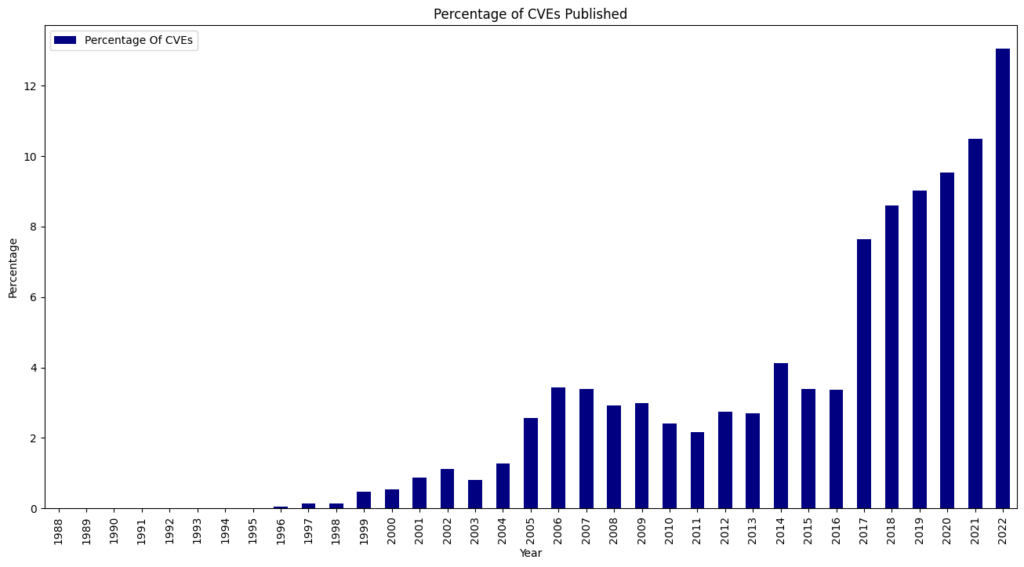
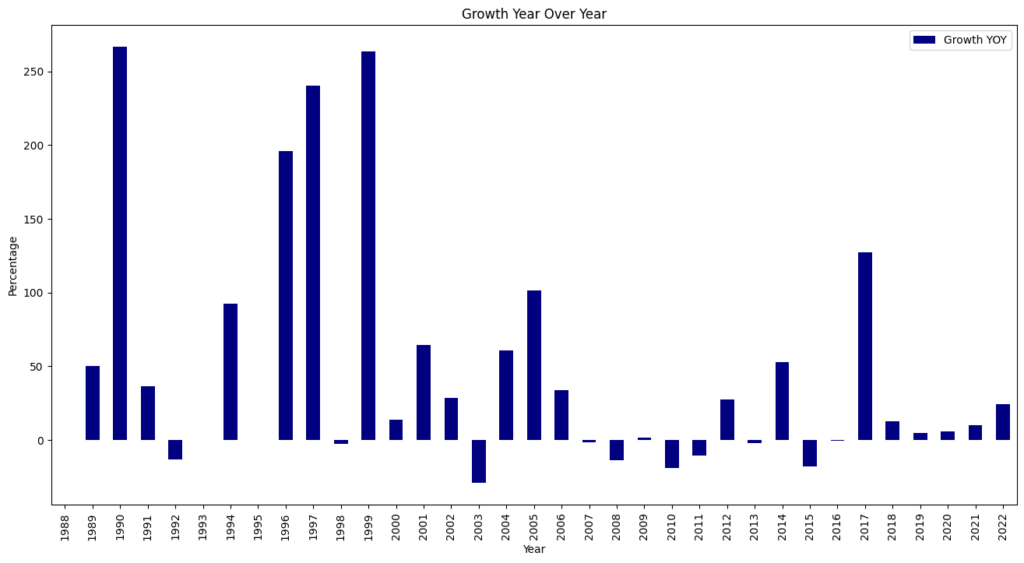
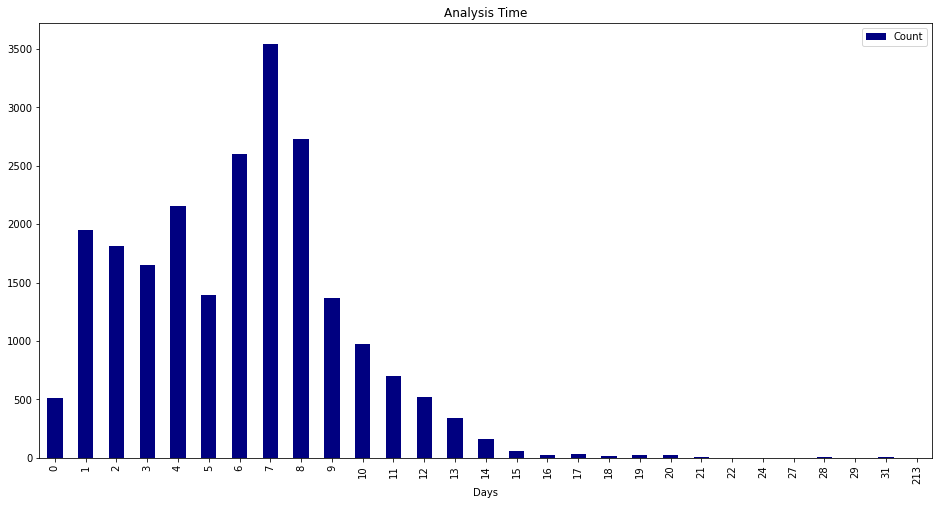
I patiently waited for an announcement about the consortium and for the enrichment of CVEs to start again. Neither happened (The NVD did analyze 167 CVEs in April, but 120 CVEs per day were published). On April 25th, the NVD posted an update saying it was still committed to enriching CVEs.
At RSAC in May, CISA announced they would start a program called Vulnrichment and enrich all CVEs that a CNA did not. They have started publishing CVE data they produced in a GitHub Repository and will start publishing it directly to CVE records as an Authorized Data Publisher (ADP). A week ago, I sat through a CVE Automation Working Group meeting where they walked through the plan, and I was once again hopeful that this would help elevate the backlog of CVEs needing enrichment and make their ADP the new source of truth for enrichment data. I started sharing this information and consulting people they would need to update their products to use the new CVE 5.1 Schema to ingest this data.
Yesterday, the NVD posted an announcement on its website stating that it had awarded a contract for additional processing support. The additional support would allow them to return to the processing rates they maintained before February 2024 within the next few months. They will work with CISA to eliminate the backlog by September 30th.

So, Who Is Going To Enrich CVEs?
In the last 100 days, I have spent a lot of professional equity telling people:
- We Will Know After Vulncon.
- NVD Announced They Will Start Enriching CVEs In A Few Days.
- I Don’t know What Is Going On With NVD.
- CISA Announced They Are Doing Vulnrichment.
- NVD Announced They Will Start Enriching CVEs In A Few Months.
At this point, I don’t know who will enrich CVE data in the future, how they will do it, or whether the data will be correct or useful. This is a terrible place to be.